
在为语言领域带来变革之后,Transformer 正在进军视觉领域,但其也有着高计算成本的问题。近日,威斯康星大学麦迪逊分校一个研究团队提出了 Eventful Transformer,可通过在视觉 Transformer 中利用时间冗余来节省成本。

图片来源:由无界 AI生成
Transformer 一开始是为自然语言处理任务设计的,但现在却已经被广泛用于视觉任务。视觉 Transformer 在一系列视觉识别任务上实现了出色的准确度,并在图像分类、视频分类和目标检测等任务上取得了当前最优的表现。
视觉 Transformer 的一大缺点是计算成本高。典型的卷积网络(CNN)处理每张图像需要数十 GFlops,而视觉 Transformer 所需的往往会多上一个数量级,达到每张图像数百 GFlops。在处理视频时,由于数据量巨大,这个问题更为严重。高昂的计算成本让视觉 Transformer 难以被部署到资源有限或有严格延迟需求的设备上,这就限制了这项技术的应用场景,否则我们已经有一些激动人心的应用了。
在近期一篇论文中,威斯康星大学麦迪逊分校的三位研究者 Matthew Dutson、Yin Li 和 Mohit Gupta 首先提出可以在后续输入之间使用时间冗余来降低视觉 Transformer 在视频应用中的成本。他们也发布了模型代码,其中包含用于构建 Eventful Transformer 的 PyTorch 模块。 
时间冗余:首先假设有一个视觉 Transformer,其可以逐帧或逐视频片段地处理视频序列。这个 Transformer 可能是简单的逐帧处理的模型(如目标检测器)或是某个时空模型的中间步骤(如 ViViT 的分解式模型的第一步)。不同于一个输入就是一个完整序列的语言处理 Transformer,在这里,研究者的做法是随时间为 Transformer 提供多个不同的输入(帧或视频片段)。
自然视频包含显著的时间冗余,即后续帧之间的差异很小。尽管如此,包括 Transformer 在内的深度网络通常都会「从头开始」计算每一帧。该方法会丢弃之前推理获得的潜在相关信息,浪费极大。故而这三位研究者设想:是否可以复用之前计算步骤的中间计算结果来提升处理冗余序列的效率?
自适应推理:对于视觉 Transformer 以及一般意义上的深度网络而言,推理成本通常由架构决定。然而在现实应用中,可用的资源可能会随时间而变化,比如可能因为存在相竞争的进程或电源发生变化。如此一来,可能就存在运行时修改模型计算成本的需求。在这项新成果中,研究者设定的一大主要设计目标便是适应性 —— 其方法可实现对计算成本的实时控制。下图 1(底部)给出了在视频处理过程中修改计算预算的示例。 
Eventful Transformer:本文提出了 Eventful Transformer,这类 Transformer 能利用输入之间的时间冗余来实现高效且自适应的推理。Eventful 这一术语的灵感来自事件相机(event camera),这种传感器能在场景变化时离散地记录影像。Eventful Transformer 会跟踪随时间发生的 token 层面的变化情况,并在每个时间步骤有选择性地更新 token 表征和自注意力映射图。Eventful Transformer 的模块中包含一种门控模块,用于控制运行时间被更新 token 的数量。
该方法可用于现成的模型(通常无需再训练)并且兼容许多视频处理任务。研究者也进行了实验论证,结果表明 Eventful Transformer 可用于现有的当前最佳模型,在极大降低它们的计算成本的同时还能维持其原有的准确度。
Eventful Transformer
这项研究的目标加速用于视频识别的视觉 Transformer。在这个场景中,视觉 Transformer 需要反复处理视频帧或视频片段,具体的任务包括视频目标检测和视频动作识别等。这里提出的关键思想是利用时间冗余,即复用之前时间步骤的计算结果。下面将详细描述如何通过修改 Transformer 模块来使其具备感知时间冗余的能力。
token 门控:检测冗余
这一小节将介绍研究者提出的两种新模块:token 门和 token 缓冲器。这些模块让模型可以识别和更新自上次更新后有明显变化的 token。
门模块:该门会从输入 token N 中选择一部分 M 发送给下游层执行计算。其记忆中维护着一个参照 token 集,记为 u。这种参照向量包含每个 token 在其最近一次更新时的值。在每个时间步骤,比较各个 token 与其对应的参照值,其中与参照值相差较大的 token 获得更新。
现在将该门的当前输入记为 c。在每个时间步骤,按照以下流程更新门的状态并决定其输出(见下图 2): 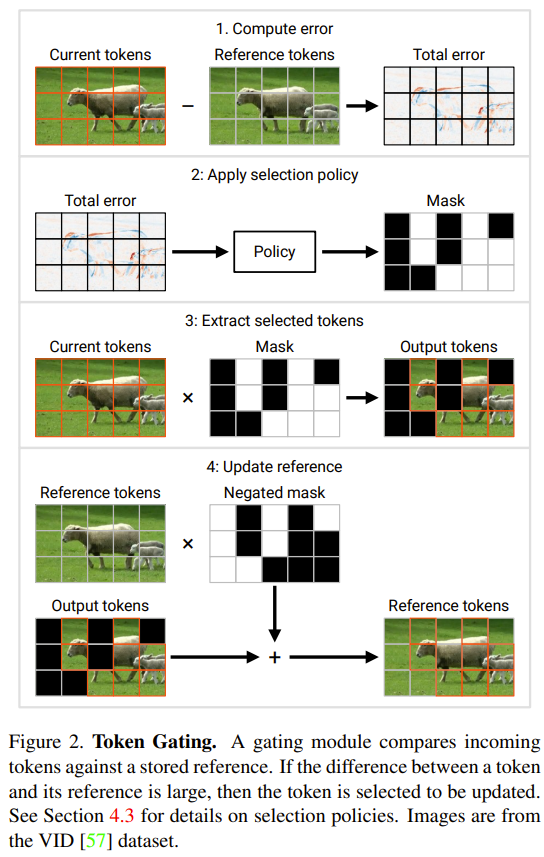
1. 计算总误差 e = u − c。
2. 对误差 e 使用一个选取策略。选择策略返回一个二元掩码 m(相当于一个 token 索引列表),表示其中哪 M 个 token 应被更新。
3. 提取出上述策略选取的 token。图 2 中将其描述为乘积 c×m;在实践中则是通过沿 c 的第一个轴执行「gather」操作来实现。这里将收集到的 token 记为 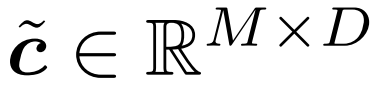
,这就是该门的输出。
4. 将参照 token 更新成所选 token。图 2 将这个过程描述为 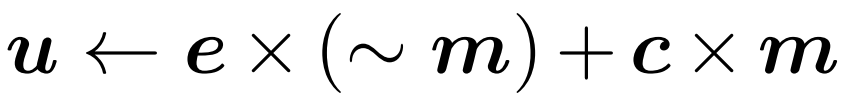
;在实践中使用的操作则是「scatter」。在第一个时间步骤,门会更新所有 token(初始化 u ← c 并返回 c˜ = c)。
缓冲器模块:缓冲模块维护着一个状态张量 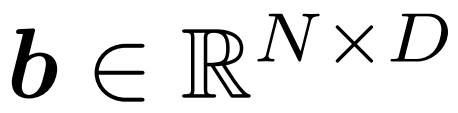
,其跟踪的是每个输入 token 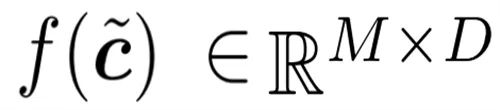
时,该缓冲器将来自 f (c˜) 的 token 分散到其在 b 中对应位置。然后它返回更新后的 b 作为其输出,参见下图 3。 
研究者将每个门与其后的缓冲器组成一对。这里给出一种简单的使用模式:门的输出 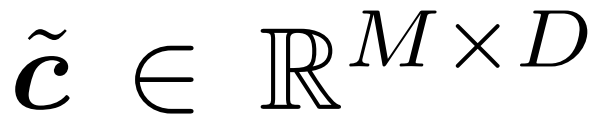
被传递给一系列针对各个 token 的运算 f (c˜);然后将所得到的张量 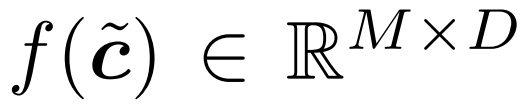
传递给一个缓冲器,其将恢复完整的形状。
构建可感知冗余的 Transformer
为了利用上述时间冗余,研究者提出了一种对 Transformer 模块的修改方案。下图 4 展示了 Eventful Transformer 模块的设计。该方法可以加速针对各个 token 的运算(如 MLP)以及查询 - 键值和注意力 - 值乘法。 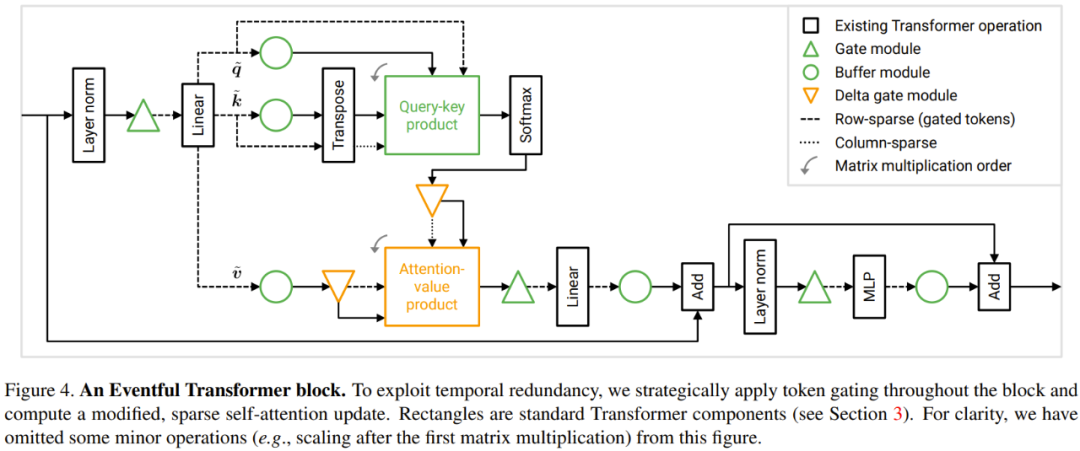
在针对各个 token 的运算 Transformer 模块中,很多运算都是针对各个 token 的,也就是说它们不涉及到 token 之间的信息交换,其中包括 MLP 和 MSA 中的线性变换。为了节省计算成本,研究者表示可以跳过未被门选取的 token 的面向 token 的运算。由于 token 之间的独立性,这不会改变对所选 token 的运算结果。参见图 3。
具体来说,针对各个 token 的运算(包括 W_qkv 变换、W_p 变换和 MLP)的连续序列,研究者使用了一对门 - 缓冲器。注意,他们还在 skip 连接之前添加了缓冲器以确保两个加法操作数的 token 是正确对齐的。
针对各个 token 的运算的成本正比于 token 的数量。门可将这个数量从 N 降至 M,也就将下游的针对各个 token 的运算的计算成本降低了 N/M 倍。
查询 - 键值的积:现在来看看查询 - 键值积 B = q k^T。
下图 5 展示了稀疏地更新查询 - 键值积 B 中一部分元素的方法。 
这些更新的总体成本为 2NMD,相较而言,从头开始计算 B 的成本为 N^2D。注意,新方法的成本正比于 M,即门选取的 token 的数量。当 M < N/2 时(此时更新的 token 不到总量一半),可节省计算量。
注意力 - 值的积:研究者为此提出了一种基于增量 ∆ 的更新策略。
下图 6 展示了新提出的高效计算三个增量项的方法。 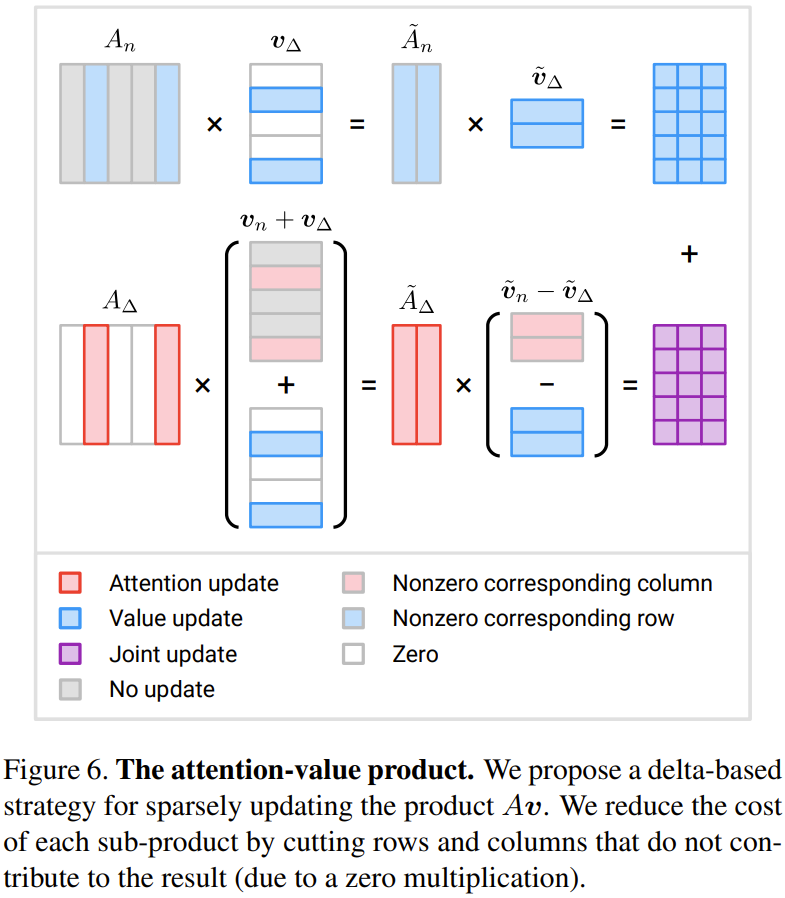
同样当 M < N/2 时,可节省计算量。
token 选取策略
Eventful Transformer 的一大重要设计是其 token 选取策略。给定一个门误差张量 e,这样一个策略的目标是生成一个掩码 m,其中指示了应当被更新的 token。具体的策略包括:
Top-r 策略:该策略选取 r 个误差 e 有最大范数的 token(这里使用的是 L2 范数)。
阈值策略:该策略选取误差 e 的范数超过一个阈值 h 的所有 token。
其它策略:更复杂精细的 token 选取策略可实现更好的准确度 - 成本权衡,比如可以使用一个轻量级策略网络来学习一个策略。但是,训练策略的决策机制的难度可能很大,因为二元掩码 m 一般是不可微分的。另一个思路是使用重要度分数作为选取的参考信息。但这些想法都还有待未来研究。
实验
研究者用实验评估了新提出的方法,具体使用的任务是视频目标检测和视频动作识别。
下图 7 展示了视频目标检测的实验结果。其中正轴是计算节省率,负轴是新方法的 mAP50 分数的相对减少量。可以看到,新方法用少量的准确度牺牲换来了显著的计算量节省。 
下图 8 给出了在视频目标检测任务上的方法比较和消融实验结果。 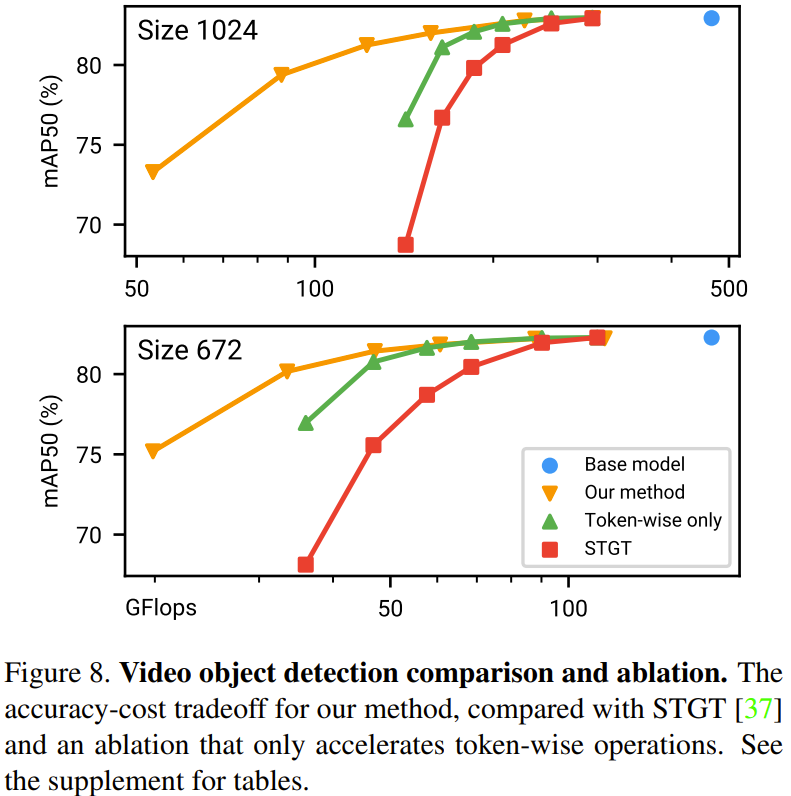
下图 9 给出了视频动作识别的实验结果。 
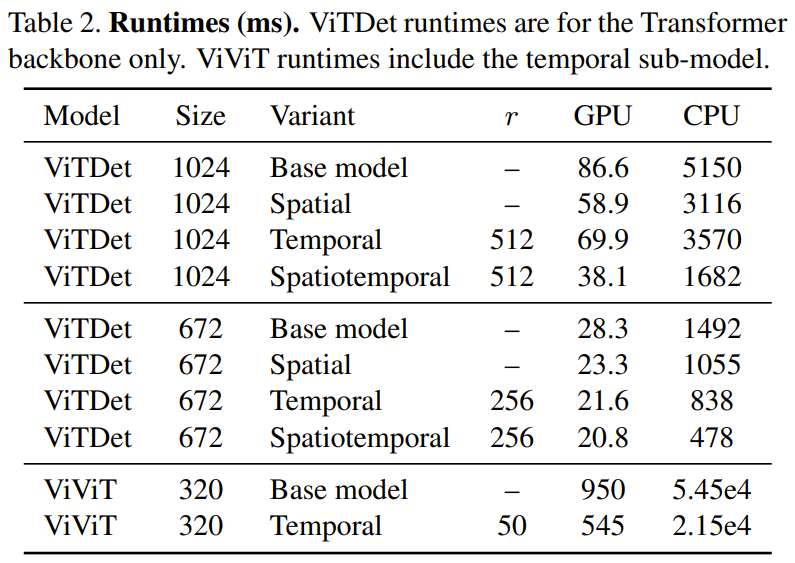
下表 2 给出了在一台 CPU(Xeon Silver 4214, 2.2 GHz)和一台 GPU(NVIDIA RTX3090)上运行时间(毫秒)结果,可以看到时间冗余在 GPU 上带来的速度提升可达 1.74 倍,在 CPU 上带来的提升可达 2.47 倍。
本文来自用户投稿,不代表币大大立场,如若转载,请注明出处:https://czxurui.com/zx/89900.html

发表回复
评论列表(0条)